PAPER/TALK: GPU-Accelerated Particle-in-Cell Code on Minsky
During this year’s International Supercomputing Conference (ISC) in June in Frankfurt, I attended a workshop called International Workshop on OpenPOWER for HPC (IWOPH). I submitted and presented a paper titled GPU-Accelerated Particle-in-Cell Code on Minsky, which is now released (see below for PDF).
The workshop was about use cases of OpenPOWER systems (mainly, IBM’s POWER8NVL processor) in the context of high-performance computing. With our JURON cluster at JSC 1, this is quite fitting. A good chance, to revisit my port of JuSPIC to OpenACC, test it well, and write about it. You’ve read already about JuSPIC+OpenACC here on the blog before.
The paper goes through the work I already did before related to JuSPIC with OpenACC; i.e. the challenges of formulating the source code in a way that OpenACC can efficiently generate GPU-accelerated functions and my decision, to eventually move over to CUDA Fortran 2.
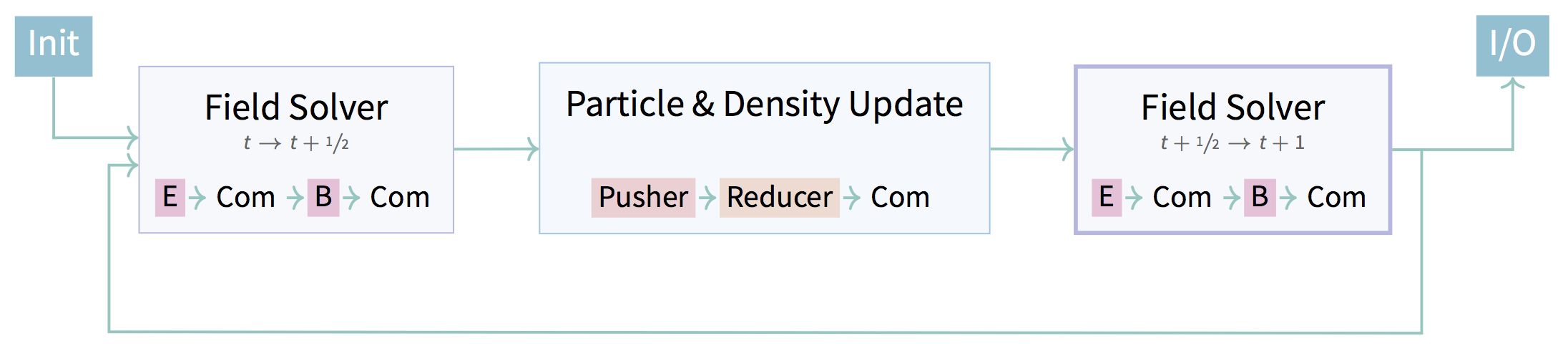
I run through the different optimizations I evaluate in order to speed things up, looking closely on different stages of the processing pipeline (data allocation, conversion, copy, processing, copy, conversion). Turns out, a structure-of-array approach is the fastest data container to crunch numbers with on the GPU device. Who would’ve thought – but there actually are some interesting and even unexpected results.
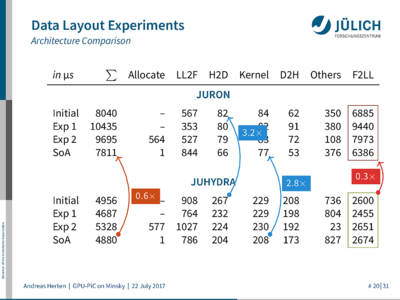 On of the unexpected results is that the conversion of the data structure takes an awful lot of time. Background: JuSPIC is written with one piece of data pointing to the next piece of data in a chain (a linked list). This is quite natural, but not optimal for modern computer architectures. Instead of data potentially scattered throughout memory, they want data packed closely together in memory so that as much data as possible can be fetched with as few instructions as possible. To achieve good performance, I convert data from JuSPIC’s linked list as soon as it enters the GPU-accelerated scope, do stuff, and convert it back afterwards. And, now back to the unexpected result, especially this back-conversion turns out to be very slow on the system tested (JURON).
On of the unexpected results is that the conversion of the data structure takes an awful lot of time. Background: JuSPIC is written with one piece of data pointing to the next piece of data in a chain (a linked list). This is quite natural, but not optimal for modern computer architectures. Instead of data potentially scattered throughout memory, they want data packed closely together in memory so that as much data as possible can be fetched with as few instructions as possible. To achieve good performance, I convert data from JuSPIC’s linked list as soon as it enters the GPU-accelerated scope, do stuff, and convert it back afterwards. And, now back to the unexpected result, especially this back-conversion turns out to be very slow on the system tested (JURON).
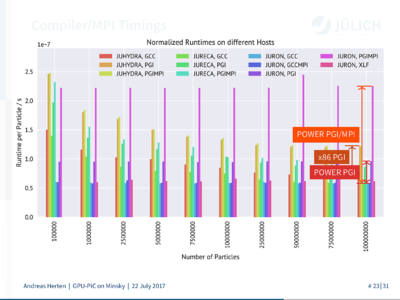 Because things happen as they always do, I only recognized that during the last couple of days before the paper deadline. So, as far as time allowed for it, I did quite a few tests together with my colleagues. And we were able to pin-point were the issues comes from, studying the generated assembly, and could eventually integrate a temporary workaround. 3 I also filed a bug report with the compiler vendor, which got fixed two weeks ago. I do still need to test it, though.
Because things happen as they always do, I only recognized that during the last couple of days before the paper deadline. So, as far as time allowed for it, I did quite a few tests together with my colleagues. And we were able to pin-point were the issues comes from, studying the generated assembly, and could eventually integrate a temporary workaround. 3 I also filed a bug report with the compiler vendor, which got fixed two weeks ago. I do still need to test it, though.
 In the last part of the paper I model JuSPIC’s GPU performance by simple performance models. I look at the effective bandwidth of the application on different GPU architectures. In addition, I study the dependency on GPU clock rates. For sure the (then) latest GPU we had access to, the NVIDIA Tesla P100, is the best choice for a GPU in JuSPIC’s case. So many multiprocessors, so much bandwidth.
In the last part of the paper I model JuSPIC’s GPU performance by simple performance models. I look at the effective bandwidth of the application on different GPU architectures. In addition, I study the dependency on GPU clock rates. For sure the (then) latest GPU we had access to, the NVIDIA Tesla P100, is the best choice for a GPU in JuSPIC’s case. So many multiprocessors, so much bandwidth.
The hunt for the allocation bug was quite involving, with different compiler versions, systems, system architectures, and MPIs on top. I think it was just luck that we noticed that the performance reduction was related to the specific MPI. Bug hunt feels always like Sherlock Matrix.
The paper is available at Springer, both in web and in PDF form as part of the High Performance Computing book. Unfortunately it is not Open Access. But I’m allowed to share the pre-print of the document, which is attached to the entry in Jülich’s library, JUSER, or here. 4
I presented the paper at the workshop in a talk, which can be found below (and on JUSER). For a first time, I created a notes version of the talk, which includes additional content not on the presented slides but things I talked about – intended for after-talk readers. Using LaTeX Beamer this is quite easy to do, and a good addition IMHO. More on that soon™ in a dedicated post.
-
A node of JURON is based on Minsky servers, the cluster has 18 of them. ↩
-
Which was actually closer to the original source code than the OpenACC-optimized Fortran code. ↩
-
The quickest one was using the linkers
LD_PRELOADenvironment variable to inject a differentmalloc()function… ↩ -
The editors decided to reduce white space in my tables and not use
booktabsas the LaTeX package. So, the nicer tables are in the pre-print version… ↩