»The data analyst's three foundations in Python«
Matplotlib • Pandas • Jupyter Notebook
Matplotlib¶
- Standard for plotting with Python
- Recently v. 2.0.0 released
- → https://matplotlib.org/index.html
Using the global API¶
- Using the MATLAB-like interface
- Everything works through
plt.…
import matplotlib.pyplot as plt
x = range(10)
y = [i**2 for i in range(10)]
plt.plot(x, y)
plt.show()
Option Showcase¶
import numpy as np
x = np.arange(0, 100, 0.2)
y = np.sin(np.sqrt(x))
plt.plot(x, y, color="green")
plt.ylim([-0.6,1.1])
plt.xlabel("Numbers")
plt.ylabel("$\sin(\sqrt{Numbers})$")
plt.show()
Object API¶
- Instead of operation on global objects with
plt, rather useFigureandAxis(axes ≈ plots) - Cleaner approach (IMHO)
- Used under the hood of global API by leveraging
plt.gca().…(get current axis)
x = np.linspace(0, 2*np.pi, 400)
y = np.sin(x**2)
fig, ax = plt.subplots()
ax.plot(x, y)
ax.set_title('Use like this')
ax.set_xlabel("Numbers again")
Multiple Plots¶
fig, (ax1, ax2) = plt.subplots(nrows=1, ncols=2, sharey=True)
ax1.plot(x, y)
ax1.set_title('Default Plot Style')
ax2.scatter(x, y, marker="D")
ax2.set_title('Scattered (Diamonds)')
fig.suptitle("Two Plots in One!")
Pandas¶
Introduction
Introduction¶
pandas is an open source, BSD-licensed library providing high-performance, easy-to-use data structures and data analysis tools for the Python programming language.
- Most important feature:
DataFrames and operations with them - → http://pandas.pydata.org/
import pandas as pd
Creating a DataFrame¶
Using a dictionary as an input
frame = pd.DataFrame({
"A": 1.2,
"B": pd.Timestamp('20170503'),
"C": [(-1)**i * np.sqrt(i) + np.e * (-1)**(i-1) for i in range(5)],
"D": pd.Categorical(["This", "column", "has", "entries", "entries"]),
"E": "Same"
})
frame
Also available: .read_csv and .read_excel
Popular Functions on Frames¶
frame.describe()
frame.head(2)
Popular Functions on Frames II¶
frame.transpose()
frame.sort_values("C")
Popular Functions on Frames III¶
round(frame,2)
frame.round(2)
frame.sum()
frame.round(2).sum()
Popular Functions on Frames IV¶
print(frame.round(2).to_latex())
Index, Columns¶
frame["NewIdx"] = pd.date_range('20170504', periods=5)
frame.head(3)
Index, Columns II¶
frame = frame.set_index("NewIdx") # Also: inplace=True
frame.head(3)
frame.index
frame.columns
Slicing¶
Select only column "A"
frame["A"]
Select columns "A" and "C"
frame[["A", "C"]].sort_values("C")
Slicing II¶
frame[1:3]
frame.loc["2017-05-06"]
frame.iloc[2]
Slicing III¶
frame[frame["C"] > 0]
frame[(frame["C"] > 0) & (frame["D"] == "has")]
Plotting¶
frame[["A", "C"]].head(3)
frame[["A", "C"]].plot()
Plotting II¶
frame[["A", "C"]].plot(
color=["red", "green"],
style=[".--","*"],
grid=True,
secondary_y=["C"]
)
Plotting III¶
frame[["A", "C"]].plot(kind="bar")
Plotting III (2)¶
frame[["A", "C"]].plot(kind="bar", stacked=True)
Plotting III (3)¶
frame[["A", "C"]].reset_index().plot(kind="bar", subplots=True, figsize=(6,2))
Further
kinds:barh,box,hist,kde(a better histogram!),scatter; more: http://pandas.pydata.org/pandas-docs/stable/generated/pandas.DataFrame.plot.htmlInstead of
.plot(kind="bar"), also possible:.plot.bar()
Advanced Plotting¶
Combine Pandas & Matplotlib¶
Combine Pandas and Matplotlib by letting Pandas draw to an axis with ax
fig, ax = plt.subplots()
frame[["A", "C"]].plot(kind="bar", ax=ax)
ax.set_xlabel("Datetime")
ax.set_ylabel("Value")
fig.savefig("barplot.pdf")
Combination II¶
fig, (ax1, ax2, ax3) = plt.subplots(ncols=3, nrows=1, figsize=(12,3))
ax1 = frame["A"].plot.line(ax=ax1)
ax2 = frame["C"].plot.box(ax=ax2)
ax3 = frame["C"].plot.hist(ax=ax3, color="orange")
fig.suptitle("Stupid plots")
Seaborn¶
Seaborn is a library for making attractive and informative statistical graphics in Python
- Provides plotting interfaces
- And sets nice defaults
- Also: Colormaps
- → http://seaborn.pydata.org/
import seaborn as sns
sns.set(rc={"figure.figsize": (5, 3)})
frame["C"].plot(marker="s", linestyle="--")
Seaborn Color Palette¶
frame["G"] = [(-1)**i * np.sqrt(i) + np.pi * (-1)**(i-1) for i in range(len(frame.index))]
frame["H"] = [(-1)**i * np.sqrt(i) + np.pi * (-1.1)**(i-1) for i in range(len(frame.index))]
with sns.color_palette("hls", 2):
fig, ax = plt.subplots()
sns.regplot(x="C", y="G", data=frame, ax=ax)
sns.regplot(x="C", y="H", data=frame, ax=ax)
Seaborn Color Palette II¶
sns.palplot(sns.color_palette())
sns.palplot(sns.color_palette("hls", 10))
sns.palplot(sns.color_palette("hls", 20))
sns.palplot(sns.color_palette("Paired", 10))
Seaborn Color Palette III / KDE Plot¶
x, y = np.random.multivariate_normal([0, 0], [[1, -.5], [-.5, 1]], size=300).T
cmap = sns.cubehelix_palette(light=1, as_cmap=True)
sns.kdeplot(x, y, cmap=cmap, shade=True);
Seaborn Color Palette IV / Jointplot¶
sns.jointplot(x=x, y=y, kind="reg")
Complex Data¶
Some real data…¶
Some PAPI counters for different number of particles (=program run lengths), compiled with different compilers
dfCounters = pd.read_csv("juron-jube-add_one_to_list.csv")
dfCounters.head(2)
dfCounters = dfCounters.rename(columns={
"modules": "Modules",
"compiler": "Compiler",
"n_particles": "Number of Particles",
"hwc": "Counter Name",
"HWC": "Counter Value"
})
dfCounters.head(2)
Massaging¶
I want some relative values…
dfCounters["Counter Value (rel.)"] = dfCounters["Counter Value"] / dfCounters["Number of Particles"]
dfCounters.head(2)
Some Values¶
Plot relative values of PAPI_TOT_CYC for gfortoran
dfCounters[
(dfCounters["Compiler"] == "gfortran")
&
(dfCounters["Counter Name"] == "PAPI_TOT_CYC")
]["Counter Value (rel.)"]\
.plot(marker="P")
More Values¶
Plot same relativ values, but also those of counter PAPI_TOT_INS
dfCounters[
(dfCounters["Compiler"] == "gfortran")
&
((dfCounters["Counter Name"] == "PAPI_TOT_CYC") | (dfCounters["Counter Name"] == "PAPI_TOT_INS"))
]["Counter Value (rel.)"]\
.plot(marker="P")
dfCounters[
(dfCounters["Compiler"] == "gfortran")
&
((dfCounters["Counter Name"] == "PAPI_TOT_CYC") | (dfCounters["Counter Name"] == "PAPI_TOT_INS"))
].head(3)
fig, ax = plt.subplots()
ax = dfCounters[(dfCounters["Compiler"] == "gfortran") & (dfCounters["Counter Name"] == "PAPI_TOT_INS")]["Counter Value (rel.)"].plot(marker="P", ax=ax, label="PAPI_TOT_INS")
ax = dfCounters[(dfCounters["Compiler"] == "gfortran") & (dfCounters["Counter Name"] == "PAPI_TOT_CYC")]["Counter Value (rel.)"].plot(marker="o", ax=ax, label="PAPI_TOT_CYC")
ax.legend(loc="best", frameon=True, fontsize=15, framealpha=0.5)
ax.set_xlabel("Measurement number")
ax.set_ylabel("Counter Value (rel.)")
Wouldn't be cool if Pandas could do this for us?
Pivoting!¶
Basically: Combine similar categorial data in a DataFrame
dfCounters.head(2)
Some data massaging: I want to remove Modules column; but to prevent double-entries, I want to rename all mpifort Compiler entries run with module openmpi/1.10.2-pgi_16.10 loaded to PGI+MPI
dfCounters.loc[
dfCounters["Modules"].str.contains("openmpi/1.10.2-pgi_16.10")
&
(dfCounters["Compiler"] == "mpifort"),
"Compiler"
] = "PGI+MPI"
dfCounters = dfCounters.drop("Modules", axis=1)
dfCounters.head(2)
Pivoting, Actually¶
index: What should be my new index? If array → hierarchical multi-indexvalues: What value should be printed in the cellscolumns: What should be the new columns? If array → hierarchical
dfPivot = dfCounters.pivot_table(
index="Number of Particles",
values="Counter Value (rel.)",
columns=["Compiler", "Counter Name"]
)
dfPivot.head(3)
Pivot and Stack¶
Maybe getting the counters to the index side is more useful?
dfPivot.stack().head(6)
… which is the same as
dfCounters.pivot_table(
index=["Number of Particles", "Counter Name"],
values="Counter Value (rel.)",
columns="Compiler"
).head(6)
Plotting Pivoted DataFrames¶
dfPivot.plot(kind="bar", figsize=(12,5))
Plotting Pivoted DataFrames II¶
dfPivot.stack().plot(kind="bar", figsize=(11,5))
Plotting Pivoted DataFrames III¶
Focus on four counters, plot them next to each other
fig, ((ax1, ax2), (ax3, ax4)) = plt.subplots(ncols=2, nrows=2, sharex=True, figsize=(12,5))
for (ax, counter) in zip([ax1, ax2, ax3, ax4], ["PAPI_TOT_INS", "PAPI_TOT_CYC", "PAPI_L1_DCM", "PAPI_STL_ICY"]):
ax = dfPivot.stack().loc[(slice(None), counter),:].plot(kind="bar", ax=ax, legend=False)
labels = [int(label.get_text().split(",")[0][1:-1]) for label in ax.get_xticklabels()]
ax.set_title(counter)
ax.set_xlabel("Number of Particles")
ax.set_ylabel("Counter Value per Particle")
ax.set_xticklabels(labels)
Jupyter Notebooks¶
Inline Magic I¶
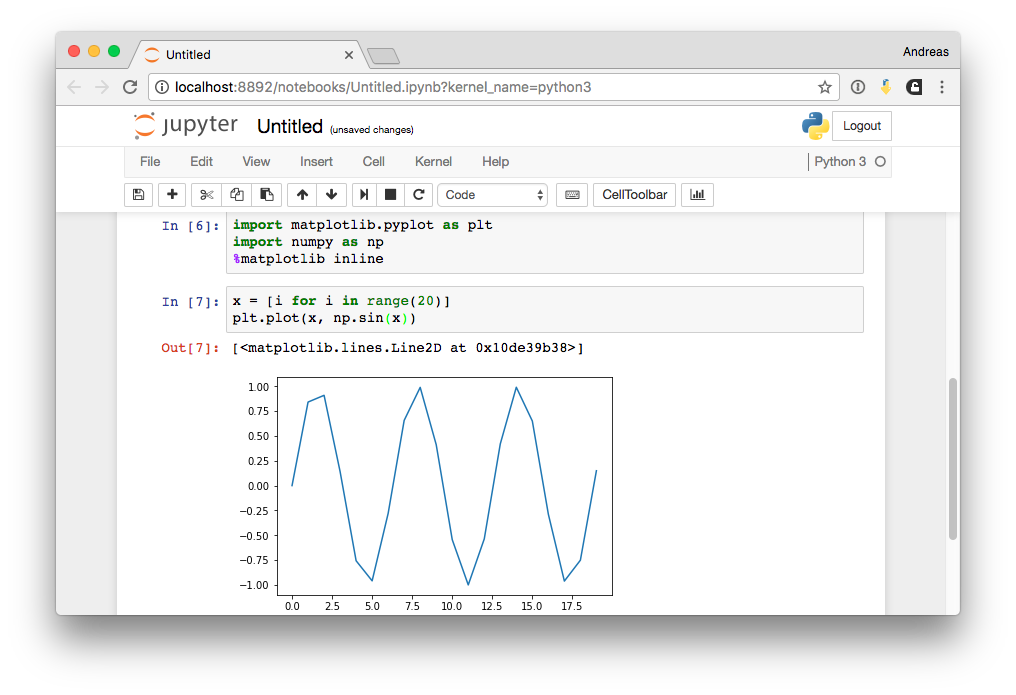
Inline Magic II¶
%timeit np.sin(range(1000))
%ls .
!pip install something
%lsmagic
Converting¶
- Notebooks are rendered at Github and our Gitlab server
- Can be converted to static HTML
- Can be converted to PDF, Markdown, reST, Slides
This presentation is one large Jupyter Notebook