-
PERMAVOST Workshop Talk: JUWELS Booster – Early User Experience

The last entry here is already four years old. Let’s face it, the blog is basically dead… For now, I need a place to collect some links for a talk. That place is here.
The last year and a half I spent my time with our JUWELS Booster supercomputer. 936 nodes, each with 4 NVIDIA A100 GPUs; 73 PFlOp/s peak. I coordinated the Early Access Program and had first-hand user experience through that.
I held quite a few talks on the topic, the most recent – and maybe publicly most interesting – one is this one. For the first PERMAVOST workshop I was invited to hold the keynote on our Early Experience with JUWELS Booster, from a performance engineering perspective.
While the second half of the talk focuses on what we’ve learned in and since the Early Access Program with respect to the applications, the first half focuses on the strangely new topology of the nodes (because of the design of the EPYC Rome processors). The second half then runs through a few applications; I highlighted an example optimization flow for JUQMES at the beginning with plenty of screenshots.
Find the slides either on the PERMAVOST website (PDF), on JUSER, or directly here (PDF). And embedded further down. There’s also an overlays-reduced handout version as usual. The (abstract of the) talk has a DOI, 10.1145/3452412.3462752.
A recording is available on YouTube; it’s also embedded further down.
As usual, the slides were made with LaTeX, which I enjoy still very much. A lot of the graphics I already had available from previous talks, but the EPYC CCX/CCD/… visualization I did just now.
→ continue reading! -
SC17 Tutorial: Application Porting and Optimization on GPU-accelerated POWER Architectures
At last year’s Supercomputing Conference we held a full-day tutorial on Application Porting and Optimization on GPU-Accelerated POWER Architectures. And this year we did it again!
While last year’s tutorial was its first-ever incarnation, we were able to fine-tune the curriculum for this year a bit. The majority of the tutorial (e.g. the overall structure: CPU in the morning, GPU in the afternoon) was the same, but we changed quite a few details.
- The introductory lecture introduced the POWER/Minsky architecture in more detail. The speaker also introduced some theoretical concepts and explained the application we were using during the hands-on parts. Because…
- … we had one common example source code for each of the 3½ hands-on sessions. Based up on this, each session taught their respective examples.
- My lecture on performance counters and measurement was reduced in time because the new introductory session took some of it. I trimmed down the content and moved lots of the stuff into the appendix. I re-did my hands-on session to focus on the new common source code – a Jacobi example – and also implemented more meaningful performance counters: Misses in L1/L2/L3 caches.
- The lecture on application optimization focused on platform-specific optimization, in addition to compiler flags. The speaker also used the common example and exploited the many cores of the processor by OpenMP.
- The GPU part was virtually untouched except for some updates. The speaker here used OpenACC to bring the application to a) a GPU and b) a number of GPUs.
- In the final presentation, the speaker presented some real-world examples using the Minsky machine and how they choose to utilize the fat node; also: Deep Learning.
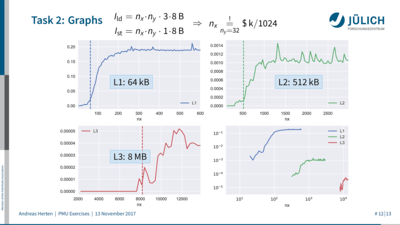 I think the changes to the content made the tutorial only more useful, as now one common theme is established. Also, we introduce modern programming models (OpenMP, OpenACC) and tools (PAPI, perf) through practical examples in passing. I like it.
I think the changes to the content made the tutorial only more useful, as now one common theme is established. Also, we introduce modern programming models (OpenMP, OpenACC) and tools (PAPI, perf) through practical examples in passing. I like it.For my part on performance counters, I was able to measure the sizes of the processor’s three cache levels by counting the number of cache misses and relating them to the source code. A rather practical learning experience, IMHO.
The evaluation is not yet out for this one, but speaking to individual people after the sessions I heard good things. It’s yet to be decided if we submit another application to host the tutorial again next year.
You can find the different talks of the tutorial at the corresponding Indico site or on JuSER. My slides are also available locally and embedded further down. Also for this one, there’s a overlay-reduced version.
→ continue reading! -
TALK: Brain Research Applications on Minsky
Right before the Supercomputing Conference in Denver, CO, I participated in a workshop titled OpenPOWER Academic Discussion Group. In it, academics invested in the OpenPOWER platform came together to present their current work and what the architecture holds for the future. Since I’m part of the POWER Acceleration and Design Centre and have hands-on experience in administrating JURON (our IBM POWER8’ Minsky server), it was a good occasion to present news from Jülich.
 My talk, Brain Research Applications on Minsky, covers a selection of applications running on JURON from the neuroscience community. JURON was acquired as a pre-commercial procurement system in the scope of the Human Brain Project, so it makes sense to use this as a POWER use-case.
My talk, Brain Research Applications on Minsky, covers a selection of applications running on JURON from the neuroscience community. JURON was acquired as a pre-commercial procurement system in the scope of the Human Brain Project, so it makes sense to use this as a POWER use-case.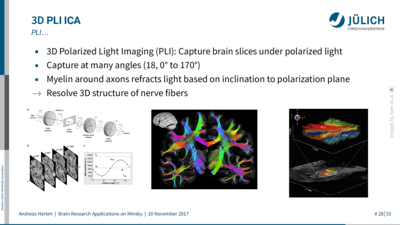 For the talk I read some background on the history of brain research, since neuroscience is not my research field at all. I also spoke to colleagues of mine involved in neuroscientific applications using JURON. They were so kind to provide me with content I could use and offered time to chat about neuroscience in general and their applications specifically. I picked applications which participated in our GPU Hackathon at the beginning of this year, since I already knew a few things about then.1
For the talk I read some background on the history of brain research, since neuroscience is not my research field at all. I also spoke to colleagues of mine involved in neuroscientific applications using JURON. They were so kind to provide me with content I could use and offered time to chat about neuroscience in general and their applications specifically. I picked applications which participated in our GPU Hackathon at the beginning of this year, since I already knew a few things about then.1 In the end, this was quite a novel experience, talking about other people’s research from a field I know little about. I did my best and hope everything turned out well. Personally, I think it went alright!
In the end, this was quite a novel experience, talking about other people’s research from a field I know little about. I did my best and hope everything turned out well. Personally, I think it went alright!Also this talk is available at JuSER, locally here, or embedded below. Since I needed to think carefully what I was going to say about each slide, I took some notes to guide my words. Based on this, there’s a version of the slides appended by notes, thanks to the
\note{}LaTeX Beamer feature.→ continue reading!-
I have not written about the GPU Hackathon here, have I? Damn. I wrote something in Jülich’s blogs, though. ↩
-
-
TALK/TUT: GPU Introduction and OpenACC Tutorial at GridKa Summer School 2017
Remember? Last year I held a talk at Karlsruhe Institute of Technology’s GridKa Summer School titled GPUs: Platform, Programming, Pitfalls introducing GPUs and stuff.
As we all know, the topic is still interesting. Also, my evaluation was quite alright, so the organizers invited me this year again to introduce GPUs at 2017’s
make science && run-titled school. In addition, they asked if I wanted to hold a tutorial on OpenACC programming. I was happy to oblige.The talk, GPU Programming 101, is basically last year’s talk with some tweaks and updates (Volta, …). But instead of running through the pitfalls – which was hard to do in the time constraints anyway – I decided rather to present some alternative GPU programming models. That is fitting with respect to the OpenACC tutorial, but also gives me a chance to present something really current in GPU programming: Higher-level, portable models.1
In the afternoon I have about five hours to host an OpenACC introduction. I present a boiled-down version of our JSC OpenACC course. I need to create a lot of slides, since I’ve never held the OpenACC introduction part of the course myself. Since I’m at it, I refine the curriculum a bit. Also, I use slightly new programming examples.2 During train travels to Karlsruhe (time is short, as usual), I add a OpenACC↔OtherGPU interoperability section to the tutorial; just in case we are finishing early. Turns out, the participants in the course were all quite apt and we indeed went through the interoperability stuff.
Again, the evaluation of talk and tutorial was quite good. The talk got a 9/10; all four tutorial-feedbacks were 10/10. Nice! Makes the effort worth it.
I made some time-consuming LaTeX fanciness in the slides, which are going into a dedicated posting.
Materials:
- Slides of the GPU-introducing talk are on JuSER, here (handout version), or embedded further down.
- Slides of the OpenACC tutorial are on JuSER, here (handout version), or embedded below the GPU slides. It’s 110 slides, so beware.3 If you’re interested in the source code of the tasks, contact me.
→ continue reading!-
I still need a chance to properly test-run Kokkos, though. ↩
-
I decide to go all-in in the method I introduced for our JSC courses for generating code. There, I have a master source code file from which the individual tasks are generated. This is done by appending the master source code with pre-processor macros which are resolved using the C partial pre-processor, cppp. When doing only one part of the tutorial, only a few tasks are generated from one master source code. But in a five-hour tutorial, where all tasks build up on each other, I ended up with eight tasks. Each accompanied by a solution version of the source code. So many
#ifdefs. So many. ↩ -
Which take like 10 minutes to typeset from scratch. Or 3 minutes for my faster computer… ↩
-
PAPER/TALK: GPU-Accelerated Particle-in-Cell Code on Minsky
During this year’s International Supercomputing Conference (ISC) in June in Frankfurt, I attended a workshop called International Workshop on OpenPOWER for HPC (IWOPH). I submitted and presented a paper titled GPU-Accelerated Particle-in-Cell Code on Minsky, which is now released (see below for PDF).
The workshop was about use cases of OpenPOWER systems (mainly, IBM’s POWER8NVL processor) in the context of high-performance computing. With our JURON cluster at JSC 1, this is quite fitting. A good chance, to revisit my port of JuSPIC to OpenACC, test it well, and write about it. You’ve read already about JuSPIC+OpenACC here on the blog before.
The paper goes through the work I already did before related to JuSPIC with OpenACC; i.e. the challenges of formulating the source code in a way that OpenACC can efficiently generate GPU-accelerated functions and my decision, to eventually move over to CUDA Fortran 2.
I run through the different optimizations I evaluate in order to speed things up, looking closely on different stages of the processing pipeline (data allocation, conversion, copy, processing, copy, conversion). Turns out, a structure-of-array approach is the fastest data container to crunch numbers with on the GPU device. Who would’ve thought – but there actually are some interesting and even unexpected results.
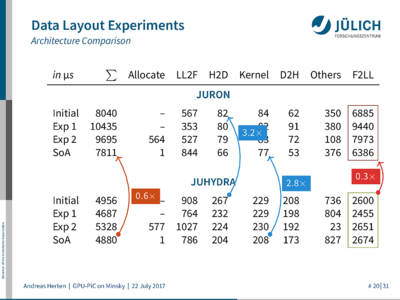 On of the unexpected results is that the conversion of the data structure takes an awful lot of time. Background: JuSPIC is written with one piece of data pointing to the next piece of data in a chain (a linked list). This is quite natural, but not optimal for modern computer architectures. Instead of data potentially scattered throughout memory, they want data packed closely together in memory so that as much data as possible can be fetched with as few instructions as possible. To achieve good performance, I convert data from JuSPIC’s linked list as soon as it enters the GPU-accelerated scope, do stuff, and convert it back afterwards. And, now back to the unexpected result, especially this back-conversion turns out to be very slow on the system tested (JURON).
On of the unexpected results is that the conversion of the data structure takes an awful lot of time. Background: JuSPIC is written with one piece of data pointing to the next piece of data in a chain (a linked list). This is quite natural, but not optimal for modern computer architectures. Instead of data potentially scattered throughout memory, they want data packed closely together in memory so that as much data as possible can be fetched with as few instructions as possible. To achieve good performance, I convert data from JuSPIC’s linked list as soon as it enters the GPU-accelerated scope, do stuff, and convert it back afterwards. And, now back to the unexpected result, especially this back-conversion turns out to be very slow on the system tested (JURON).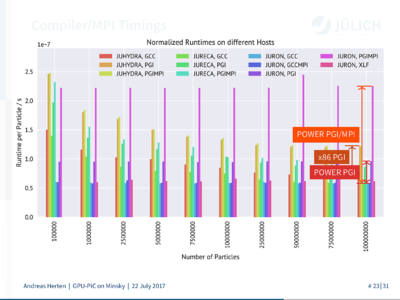 Because things happen as they always do, I only recognized that during the last couple of days before the paper deadline. So, as far as time allowed for it, I did quite a few tests together with my colleagues. And we were able to pin-point were the issues comes from, studying the generated assembly, and could eventually integrate a temporary workaround. 3 I also filed a bug report with the compiler vendor, which got fixed two weeks ago. I do still need to test it, though.
Because things happen as they always do, I only recognized that during the last couple of days before the paper deadline. So, as far as time allowed for it, I did quite a few tests together with my colleagues. And we were able to pin-point were the issues comes from, studying the generated assembly, and could eventually integrate a temporary workaround. 3 I also filed a bug report with the compiler vendor, which got fixed two weeks ago. I do still need to test it, though. In the last part of the paper I model JuSPIC’s GPU performance by simple performance models. I look at the effective bandwidth of the application on different GPU architectures. In addition, I study the dependency on GPU clock rates. For sure the (then) latest GPU we had access to, the NVIDIA Tesla P100, is the best choice for a GPU in JuSPIC’s case. So many multiprocessors, so much bandwidth.
In the last part of the paper I model JuSPIC’s GPU performance by simple performance models. I look at the effective bandwidth of the application on different GPU architectures. In addition, I study the dependency on GPU clock rates. For sure the (then) latest GPU we had access to, the NVIDIA Tesla P100, is the best choice for a GPU in JuSPIC’s case. So many multiprocessors, so much bandwidth.The hunt for the allocation bug was quite involving, with different compiler versions, systems, system architectures, and MPIs on top. I think it was just luck that we noticed that the performance reduction was related to the specific MPI. Bug hunt feels always like Sherlock Matrix.
The paper is available at Springer, both in web and in PDF form as part of the High Performance Computing book. Unfortunately it is not Open Access. But I’m allowed to share the pre-print of the document, which is attached to the entry in Jülich’s library, JUSER, or here. 4
I presented the paper at the workshop in a talk, which can be found below (and on JUSER). For a first time, I created a notes version of the talk, which includes additional content not on the presented slides but things I talked about – intended for after-talk readers. Using LaTeX Beamer this is quite easy to do, and a good addition IMHO. More on that soon™ in a dedicated post.
→ continue reading!-
A node of JURON is based on Minsky servers, the cluster has 18 of them. ↩
-
Which was actually closer to the original source code than the OpenACC-optimized Fortran code. ↩
-
The quickest one was using the linkers
LD_PRELOADenvironment variable to inject a differentmalloc()function… ↩ -
The editors decided to reduce white space in my tables and not use
booktabsas the LaTeX package. So, the nicer tables are in the pre-print version… ↩
-
-
POSTER: Accelerating Plasma Physics with GPUs – JuSPIC with OpenACC and CUDA Fortran
At GPU Technology Conference (GTC) this year I presented a poster on my acceleration work on JuSPIC with OpenACC. See below for an embed.
The main part of the poster are the different stages I went through while porting JuSPIC to OpenACC and to efficient OpenACC. It is meant as an experiences pieces outlining different strategies of acceleration at the same time.
I also present first models of JuSPIC’s performance here, but I show more on that in the IWOPH paper.
I was able to travel to GTC17 with the poster (which was awesome!), it was even chosen to be included in the Top 20 Fast Forward Program. Cool! I was worried that the non-standard design could be interpreted as somewhat unscientific. Nice that it wasn’t.
→ continue reading!
It’s unfortunate, though, that the poster submission deadline is so much earlier than the actual conference. -
Interesting Talks from GTC 17
A month ago, I traveled to San Jose, CA, to visit the GPU Technology Conference, GTC, and learn the latest on all things GPU.
The schedule was super packed and at more than one time, I wasn’t able to see some interesting talk because I was already sitting in one other interesting talk.1
Here’s a list of sessions I found interesting/noteworthy and/or want to (re)visit after the conference, sorted by topics.
Links to recordings and slides are provided. Bold indicates that I have not yet seen the talk and want to do so.I post this only today since the materials have been private up to now.2
- Volta, CUDA 9
- S7798: Inside Volta (link, recording, slides)
- S7132: CUDA 9 And Beyond (link, recording, slides)
- S7824: Developer Tools Update In CUDA 9 (link, recording, slides)
- S7622: A Robust And Scalable CUDA Parallel Programming Model [Cooperative Groups] (link, recording, slides)
- Additional read on Parallel Forall blog
- General CUDA, GPU:
- S7495: Optimizing Application Performance With CUDA Profiling Tools (link, recording, slides)
- S7122: CUDA Optimization Tips, Tricks And Techniques (link, recording, slides)
- S7445: What The Profiler Is Telling You: Optimizing Whole Application Performance (link, recording, slides)
- S7444: What The Profiler Is Telling You: Optimizing GPU Kernels (link, recording, slides)
- GPU Data Management
- S7362: Benchmarking The New Unified Memory Of CUDA 8 (link, recording)
- S7628: The Future Of GPU Data Management (link, recording, slides)
- S7285: Unified Memory On The Latest GPU Architectures (Pascal, Volta) (link, recording, slides)
- S7764: GPUs: Using HMM To Blur The Lines Between CPU And GPU Programming (link, recording, slides)
- S7128: How To Enable NVIDIA CUDA Stream Synchronous Communications Using Gpudirect (link, recording, slides)
- S7700: An Introduction To The GPU Memory Model - Presented By Acceleware (session 2 Of 4) (link, recording)
- S7628: The Future Of GPU Data Management (link, recording, slides)
- Libraries, Packages, Tools
- Multi-GPU, MPI
- S7133: Multi-GPU Programming With MPI (link, recording, slides)
- S7142: Multi-GPU Programming Models (link, recording, slides)
- S7356: MVAPICH2-GDR: Pushing The Frontier Of HPC And Deep Learning (link, recording, slides)
- S7546: Multi-GPU Programming With OpenACC (link, recording, slides)
- S7155: Optimized Inter-GPU Collective Operations With NCCL (link, recording, slides)
- Other Programming Models (OpenACC, OpenMP, OpenCL, Etc.)
- S7344: Kokkos - The C++ Performance Portability Programming Model (link, recording, slides)
- S7192: OmpSs+OpenACC: Multi-target Task-based Programming Model Exploiting OpenACC GPU Kernels (link, recording, slides)
- S7496: OpenCL At NVIDIA: Best Practices, Learnings, And Plans (link, recording, slides)
- S7626: A Simple Guideline For Code Optimizations On Modern Architectures With OpenACC And CUDA (link, recording, slides)
- S7636: Cache Directive Optimization In OpenACC Programming Model (link, recording, slides)
- Use-Cases
- S7341: Using OpenAC For NGS Techniques To Create A Portable And Easy-to-use Code Base (link, recording, slides)
- S7640: Porting C++ Applications To GPUs With OpenACC For Lattice Quantum Chromodynamics (link, recording, slides)
- S7672: OpenACC Best Practices: Accelerating The C++ NUMECA FINE/Open CFD (link, recording, slides)
- S7635: Comparison Of OpenACC And OpenMP4.5 Offloading: Speeding Up Simulations Of Stellar Explosions (link, recording, slides)
- S7478: Using OpenACC To Parallelize Irregular Algorithms On GPUs (link, recording, slides)
- S7193: Achieving Portable Performance For GTC-P With OpenACC On GPU, Multi-core CPU, And Sunway Many-core Processor (link, recording, slides)
- S7735: GPU Acceleration Of The Higrad Computational Fluid Dynamics Code With Mixed OpenACC And CUDA Fortran (link, recording, slides)
- S7382: GPUs Unleashed: Analysis Of Petascale Molecular Simulations With VMD (link, recording, slides)
- S7535: Potential Field Solutions Of The Solar Corona: Converting A PCG Solver From MPI To MPI+OpenACC (link, recording)
- AI, Machine Learning, Deep Learning, and Siblings
- S7457: Deep Learning Demystified (link, recording, slides)
- S7515: Eliminating The Regular Expression With Neural Networks (link, recording, slides)
- S7800: Leveraging The Power Of Google’s Cloud Machine Learning Service (presented By Google) (link, slides)
- S7860: Starting A Deep Learning Project (link, recording, slides)
- S7666: Learning Particle Physics By Example: Using Generative Adversarial Networks To Accelerate Physics (link, recording, slides)
- S7804: Tensorflow: Open Source Machine Learning (presented By Google) (link, recording)
- Round Tables, Panels
- Use-Cases, Applications
- Others
- Python:
- S7609: Porting After Effects To The GPU (link, recording, slides)
- S7590: Passengers: Awakening VR, When Film Meet VR (link, nothing on this :()
- S7296: Cloudlighting: Merging GPU-based Hpc With Cloud Services (link, recording, slides)
- S7329: Open-source Tools For GPU Programming Assignments In Large Classroom Settings (link, recording, slides)
- S7482: Advances In Real-time Graphics At Pixar (link, unfortunately nothing else, even though I thought they said so during the session)
- S7642: Preparing GPU-accelerated Applications For The Summit Supercomputer (link, recording, slides)
- Keynote (link)
-
The pinnacle of things was the Wednesday-4pm timeslot, when four this year new-like talks happened at the same time. Talk about parallelism. ↩
-
The GTC team changed the URLs when they made the talks and slides available publicly. So I needed to go through my nearly-ready-made post and re-do all the links. I was to lazy to do that manually, so… Python to the rescue! I did it with this Jupyter Notebook (.ipynb file). ↩
- Volta, CUDA 9
-
Data Analysis with Python
In the last few weeks I needed to crunch some data. It was structured data, so I had a reason for finally jumping into pivoting DataFrames in Pandas1 – a thing I still knew (and know…) very little about.
I’m using Python for any kinds of visualization since quite some time already. It’s so versatile, productive, and handy! #♥
After finishing my paper, I wanted to show my colleagues shortly the basics of what they need to know to massage their data and make nice-looking plots from it. With Python. A kind of Data Analysis with Python 1-0-½.
Here are the slides, which scratch the surface of Matplotlib, Pandas, and Jupyter Notebooks. Also: Seaborn. Navigate with space bar.
Open directlyThe presentation itself is done in a Jupyter Notebook. Hence the embedded HTML presentation with reveal.js, which Jupyter natively generates. If you’re looking for a more static version, there’s a PDF of it as well2. Also, the Notebook is available in this Gist, in case you’d like to see how its done.
Edit, 29 May: There’s a handy cheatsheet available in Pandas’ Github repository.
Let me know what you think of the slides. What would be your recommendations to further simplify or improve data analysis with Python? Tweet me!
-
WTF you say? Well. Read on. Or just jump ahead to the presentation. It all makes sense. I promise. ↩
-
Which were hell to compile. That’s really not the strong suit of those HTML/JS presentation frameworks (and for me a show-stopper). I used the decktape method to get a PDF from the HTML and used
pdfcropto get rid of scrollbars. ↩
-

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}